Deep Reinforcement Learning-based Image Captioning with Embedding Reward
这篇是对最新关于image caption的文章的总结。和大部分state-of-the-art的方法大相径庭的是,这篇文章没有使用Encoder-Decoder框架,而是剑走偏锋受到增强学习中actor-critic方法的启发,提出了一种新的称之为“决策制定”(decision-making)的框架。并且据他们的实验结果显示,在各种评测标准中都达到了state-of-the-art的水平。本文从增强学习中的相关概念出发,来剖析这篇文章的方法思路以及探讨这篇文章可以带给我们的启发。
Zhou Ren, Xiaoyu Wang, Ning Zhang, Xutao Lv, Li-Jia Li. “Deep Reinforcement Learning-based Image Captioning with Embedding Reward”[https://arxiv.org/abs/1704.03899]
Abstract
image caption是一个具有挑战性的问题,原因在于认知图片内容的复杂性和自然语言表达描述的多样性。最新的方法利用神经网络,已经在性能上有了很大的提升。大部分的state-of-the-art的方法都使用的是encoder-decoder的框架,这种框架利用序列递归预测模型来生成标注。这篇文章推出了一种新的叫做“决策制定”的框架,利用“策略网络”和“价值网络”共同生成标注。策略网络做局部指导,在某种状态下给出生成某个单词的概率;而价值网络做全局指导,给出某状态下所有可能的延伸的完整句子的评测。两种网络通过增强学习中actor-critic方法进行训练,训练中回报为新的视觉语义嵌入。扩展实验及分析显示,这种框架无论在何种评测标注下都表现出了不俗的性能。
Actor-cirtic
这是我之前在学习和整理policy gradient的时候挖下的坑,现在又不得不去填了。Actor-cirtic,“演员-批评家”方法,由其名称来看,actor根据当前环境进行表演,而cirtic会对进行actor进行评价,actor又根据这个评价来改变自己的表演,最终得到比较好的演出效果。作为值函数方法和策略函数方法两种方法的结合体,actor-cirtic拥有两者的优点。我们之前介绍过在policy gradient方法中增加一个baseline函数来减少方差,这里的baseline函数就是模拟的状态值函数。
actor-critic算法是一种TD method。结合了value-based和policy-based方法。policy网络是actor(行动者),输出动作(action-selection)。value网络是critic(评价者),用来评价actor网络所选动作的好坏(action value estimated),并生成TD_error信号同时指导actor网络critic网络的更新。
其中TD的作用和MC差不多,不过MC是要等到所有序列完成之后才能更新,而TD只需要几步就可以。
TD(Time Difference) method,是Monte-Carlo和Dynamic Programming 方法的一个结合。相比MC方法,TD除了能够适用于连续任务外,和MC的差异从下图可以清楚看到。MC需要回退整个序列更新Q值,而TD只需要回退1步或n步更新Q值。因为MC需要等待序列结束才能训练,而TD没有这个限制,因此TD收敛速度明显比MC快,目前的主要算法都是基于TD。下图是TD和MC的回退图,很显然MC回退的更深。
Introduction
这里介绍了很多关于encoder-decoder方法的内容,这里跳过。与encoder-decoder方法不同的是,文章的方法每次通过policy net和value net来选出最好的单词。通过value network,即使是当前概率很小的单词也可以选到,只要由它生成的完整的句子的回报高。这就避免了贪心所导致的得不到最好的句子。
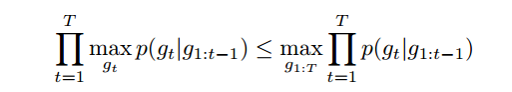
训练方法:policy network通过标准的监督学习中的交叉熵损失进行预训练,value network通过均方误差进行预训练。然后两者再通过深度增强学习进行训练。
policy network
结构如下所示
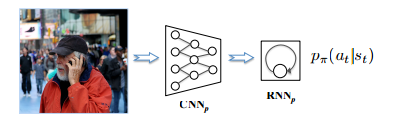
和encoder-decoder非常相似。
value network
在进行介绍之前,我们先定义一下策略p的状态值函数:当前状态下s_t执行策略p之后所能得到的期望回报。value network的目的就是逼近这个值函数,并把它作为对于当前状态的评判依据。网络结构如下所示
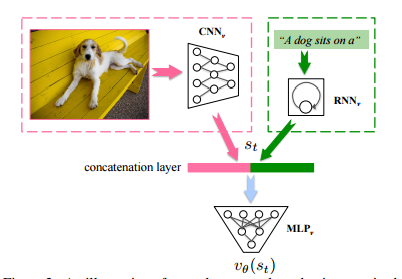
由CNN,RNN,MLP组成。状态s_t由图片信息和当前部分句子组成。
Reward defined by visual-semantic embedding
这篇文章的嵌入模型由三部分构成:CNN,RNN,线性映射层。线性映射层的作用是将图片信息向量映射到嵌入式空间。训练时按下面的损失函数训练
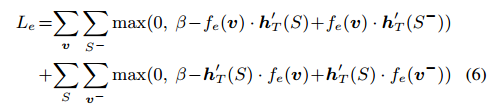
回报为向量做点积后除以它们模长之积。
Training using deep reinforcement learning
记policy networks为p,value networks为v。
p和v分两步进行训练。第一步按之前的讲的进行预训练。
第二步p和v一起通过深度增强学习进行训练。目标是最大化agent的期望总回报,利用policy gradient threom,得到
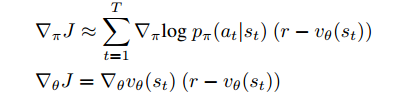
可以看到,这里v在训练p的时候作为baseline函数。这个方法可以看做是actor-cirtic,这里p为actor而v作为cirtic。
难训练的解决办法
用增强型学习来进行image caption有一个很大的问题是难训练,因为在决策制定过程中action的范围太大。为了解决这个问题,这篇文章使用了课程学习来训练actor-cirtic模型。为了逐渐教会模型去生成稳定的句子,在训练采样点的时候渐渐加大训练的难度,先通过交叉熵来训练前$T-i\cdot\Delta$个单词,然后用增强学习来训练后$i\cdot\Delta$个单词。$i$逐渐增大。
inference
这也是文章的重点之一。之前的方法,比如show and tell中用到的是beam search(聚束搜索),每次找分数排名前B个的单词,往后进行。这种方法的缺点是只会找当前分数排名高的,但可能会错过前景大的单词。为了解决这个问题,我们在分数上下文章,结合刚才讲的p和v。将原来的分数S()由生成概率改为下式
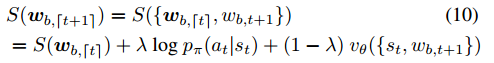
w_b为当前生成的句子,将w(t+1)拆分长两项:前t个单词组成的句子和第t+1个单词,那么分数就由着两者的分数构成,而第t+1个单词的分数由之前的p和v线性组合得到。