Holiday Paper Reading
以下两篇文章都是讲如何通过增强学习中的ac方法来进行Image Caption训练的。由于上学期期末打算舍弃原来GAN的方法,用这种方法来进行Image Caption,所以在细读师兄给的文章的基础上,又读了一篇6月份发表的相似方法的文章。希望能够通过这两篇文章对这种方法做细致的了解,为后面的实现做好准备。
Deep Reinforcement learning
[1] Zhou Ren, Xiaoyu Wang, Ning Zhang, Xutao Lv, Li-Jia Li(2017): Deep Reinforcement Learning-based Image Captioning with Embedding Reward. CoRR, abs/1704.03899, https://arxiv.org/abs/1704.03899
这篇文章是上学期师兄给我的,当时就感觉这篇文章所用的方法很好。网络结构简单,不会用到复杂的训练方法,更不会像GAN那样,训练的时候就要调很多参数。当然他们的结果也很有说服力。
之前大部分state-of-the-art的方法所使用的框架都是encoder-decoder,如show-and-tell等等。这些方法通常都是使用一个卷积神经网络来编码视觉信息,然后利用递归神经网络译码这些信息从而生成句子。在训练和推断的时候,会根据当前的隐状态最大化下一个单词的概率。这些都是之前的内容,通过show-and-tell的就可以得知其中具体的方法。当然还有一些方法在show-and-tell的基础上做了改进,使得性能更高,如我毕设所做的GAN、还有其他人的Reinforcement Learning等等。但是这些方法的框架都离不开encoder-decoder,这篇文章推出了一种新的“决策制定”框架,这种框架在每一步利用“决策网络(policy network)”和“价值网络(value network)”来共同确定下一个单词,而不是训练出一个独立的序列循环模型来生成下一个单词。
“决策网络”会在每一步根据当前状态提供下一个单词的置信度,称之为“局部指导(local guidance)”。而“价值网络”会计算出所有可能的扩展的回报,因此又称之为“全局指导(global and lookahead guidance)”。这样的价值网络的目标是希望模型能够生成和ground-truth相似的句子。这样可以避免一些由policy gradient得分不高但是扩展句子比较好的单词没有机会被选取到。下图为我们展示了上述框架。
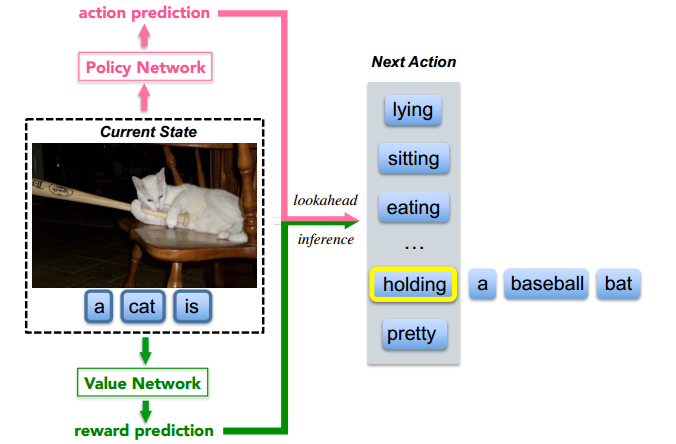
更多内容,参见Post: Deep Reinforcement Learning-based Image Captioning with Embedding Reward
本来想在github上找一下代码的,但时没有找到。作者完成这篇文章是在snap inc. 网上关于这个公司研究所的资料不多。我找到的原作者的个人主页任洲。
Actor-Critic Sequence Training
[2] Li Zhang, Flood Sung et.al(2017): Actor-Critic Sequence Training for Image Captioning. CoRR, abs/1706.09601, https://arxiv.org/abs/1706.09601
这篇文章也是利用reinfoecement learning中的actor-critor方法来进行image caption训练的,但是与上一篇文章不同的是,这篇文章仍然使用encoder-decoder框架,和之前一篇用reinforcement learning进行优化的文章相似,用metrics来代替log likehood,使用actor-critic而非policy gradient。文章首先阐述了mle方法的缺陷,之前已经讲过,一个是exposure bias,一个是交叉熵不能作为评测句子好坏的标准。
本文的模型主要包含两个部分,actor和critic,actor根据当前状态预测单词,critic根据对当前的状态进行打分,从而训练actor。当然具体怎么打分的,还是依靠某种metric的得分,如文中的CIDEr。
文章所使用的方法并不复杂,但是最后的效果却很好,在一些metrics上的表现高于其他方法。如下表所示:
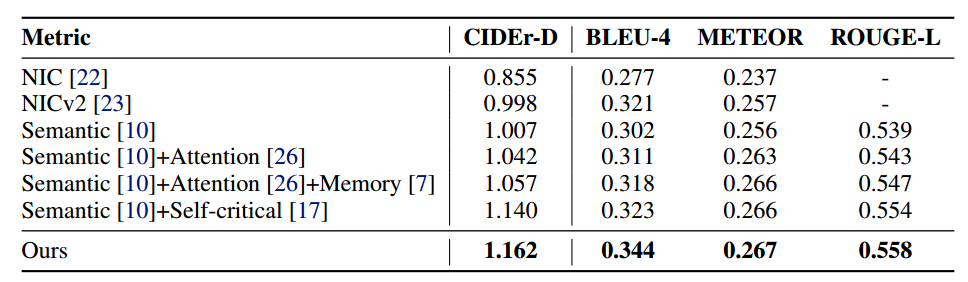
文章中一些细节的部分还没有搞清楚。目前来看,这篇文章所用的方法看起来比较简单,实现起来也比较容易。和上一篇文章相比,我想先实现这篇文章的方法。可惜的是这篇文章也没有找到源代码。