Dectection
- obj2text’s evaluation, finished.
- detection theses including R-CNN, Fast R-CNN, Faster R-CNN.
R-CNN
[1] Ross Girshick, Jeff Donahue, Trevor Darrell, Jitendra Malik(2013): Rich feature hierarchies for accurate object detection and semantic segmentation. CoRR, abs/1311.2524, https://arxiv.org/abs/1311.2524
作为Fast R-CNN和Faster R-CNN的基础,首先学习了R-CNN篇文章。“RCNN可以看作是RegionProposal+CNN这一框架的开山之作”“Region CNN(RCNN)可以说是利用深度学习进行目标检测的开山之作”。
“Can a large convolutional neural network trained for whole-image classification on ImageNet be coaxed into detecting objects in PASCAL?”这篇文章给出的答案是yes,并且给出了将计算机视觉领域自下而上生成推荐区域的方法与CNN相结合的系统,称之为R-CNN,即Regions with CNN features. 获得了很好的效果。
下图是整个R-CNN的框架
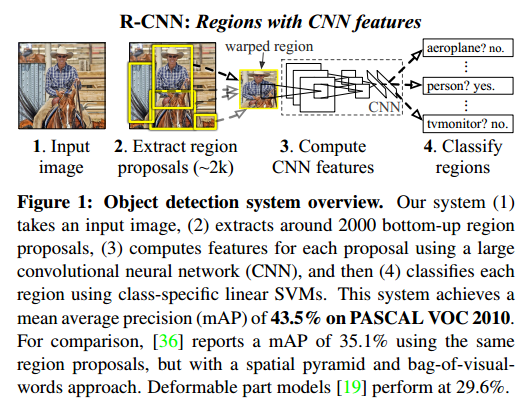
模型具体细节
Region Proposals
其实做Region Proposals的方法有很多,包括objectness, selective search, category-independent object proposals, CPMC等等。本文采用了在PASCAL detection任务上的表现不错的selective search。但是这篇文章并没有给出SS(selective search)是具体是怎么去得到这2k块左右的提议区域的。
这篇[blog]对此做了一个总结。SS的基本思路如下:
- 使用一种过分割手段,将图像分割成无数个小区域;
- 根据现有的小区域,根据某种规则(颜色、纹理、合并后总面积小的、合并后在其BBOX中所占比例大的)合并可能性最高的两个区域。这里要保证合并操作的尺度是均匀的,否则容易出现一个大区域逐渐“吃掉”其他小区域;
- 重复第2步直到整张图片合成一个区域;
- 输出所有曾经存在过的区域,即为候选区域。
当然,Region Proposals和后面的步骤是独立的,并且这一部分操作与目标类别没有任何关系。使用SS之外的其他方法也是可以的。另外,由于这一步操作耗时巨大(2s on cpu),一般会在这一步处理一下,将处理结果放在硬盘上方便后面的步骤使用。
Feature extraction
对于每个候选区域,通过CNN将之转化为一个4096维的feature vector。文中使用的CNN可接受的输入是$244\times244$的RGB图像,所以要先将形形色色的候选区域转化为$244\times244$大小的。文中所使用的方法简单直接——不管候选区域的大小、横纵比是多少,直接将边框扭曲到所需大小。实际上这种方法得到的结果的扭曲程度比想象中要小。
Inference
每个候选区域对于每一类,我们将刚才计算得到的feature vector通过SVM得到这个候选区域属于这一类的概率。这样每个候选区域就会得到其属于某一类的分数。然后分别对于每一类,采用greedy non-maximum supression(贪婪的非极大值抑制法)从而去舍弃多余的候选区域。如文中所述,如果一个候选区域在某一类上和另一个分数更高的区域的交并比(IoU)大于某一个阈值(文中的实验是0.3),那么它就会被舍弃。
这样就会得到最终的detection的结果。
Training
CNN CNN会在imageNet上进行预训练,imageNet上的ILSVRC 2012数据集共有一千万张图片,1000类。然后为了使CNN更加适应PASCAL训练集,然后在PASCAL上的变形的推荐区域进行训练。训练参数暂且不提。
Object category classifier 考虑car的二分类,如果一张图片表示的就是car,那么这张图片就是正类,如果一张图片是背景,与car没有什么关系,那就是反类。下面主要考虑的是如果去划分那些与car部分重叠的区域。解决问题的办法是定义一个交并比(IoU)阈值,如果低于这个阈值那么我们认为这是一个反类。分类这方面是一个现象的SVM,每个类都有一个。
Fast R-CNN
[2] Ross Girshick(2015): Fast R-CNN. CoRR, abs/1504.08083, https://arxiv.org/abs/1504.08083
R-CNN耗时严重,Fast R-CNN针对R-CNN的第2大步进行优化。文章首先列举了R-CNN一些显著的缺点。
- 训练是一个多级管道(Training is a multi-stage pipeline)。也就是训练要分开多部训练。
- 训练无论是在时间上还是在空间上复杂度都很高。
- 测试的时候也很慢。
并且指出了R-CNN慢的原因:对于每个候选区域都要进行一次卷积,这些卷积的计算没有共享。SPPnet做的就是共享这些计算(这篇文章我没有看)——在整个输入的图像上计算卷积,根据计算得到的feature map投射得到某一区域的feature vector。但是SPPnet也有其显著缺点,SPPnet的训练仍然是多级的。为此作者提出了Fast R-CNN。其框架如下所示
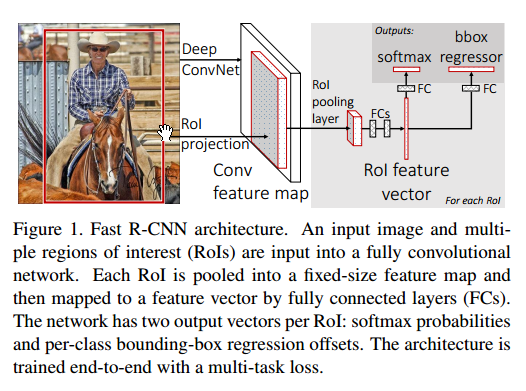
Faster R-CNN
[3] Shaoqing Ren, Kaiming He, Ross Girshick, Jian Sun(2015): Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. CoRR, abs/1506.01497, https://arxiv.org/abs/1506.01497
瓶颈是region proposal这一部分。所以这篇文章所做的主要工作是提出了Region Proposal Network(RPN)。文章给出的system包含两个模块:第1个模块是推出候选区域的全卷积网络,第2个模块为Fast R-CNN利用这些候选区域进行检测。整个模块是单一的、统一的目标检测网络,如下图所示。采用了“attention”机制,RPN会告诉Fast R-CNN模块应该注意哪一部分。
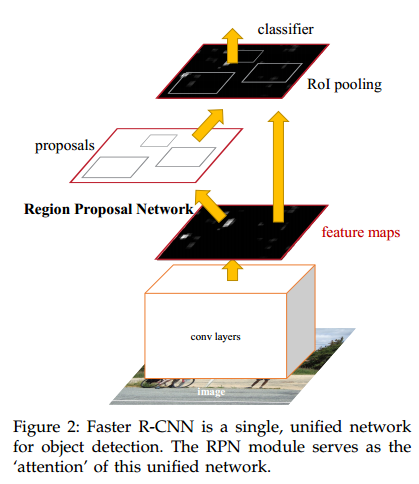
Region Porposal Networks
RPN的输入是一个任意形状的图片,其输出是矩形候选目标及其objectness分数(即该区域为任何一类物体的分数)。所使用的是全卷积网络,而全卷积网络没有全连接层。
为了得到候选区域,我们使用一个小网络在最后一层卷积层输出的feature maps上进行滑动。这个滑动窗口的输入大小是$n\times n$,然后将每一个滑动窗口映射为低维的feature(256-d for ZF and 512-d for VGG, with ReLU following)。然后这个feature会被同时送到两个姊妹全连接层,分别进行box-regression(reg)和box-classification(cls),如下图左侧所示。这里使用$n=3$,feature maps上的$3\times3$在输入图像上对应的是171或288的感受野(receptive field)。
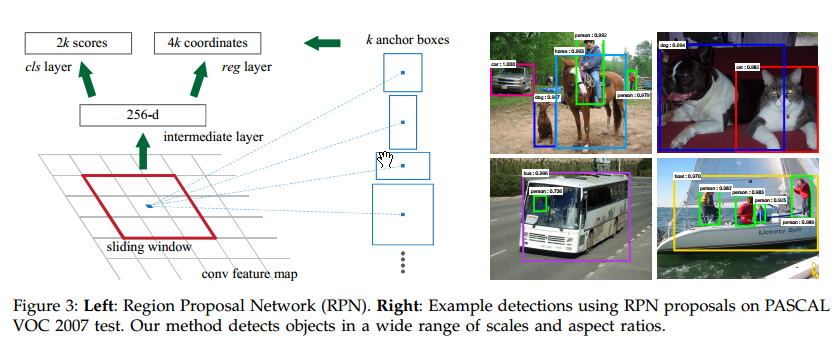
Anchors
在滑动过程中的每个位置,我们同时预测至多$k$个region proposals。由此对于reg会得到$4k$个结果,对于cls会得到$2k$个结果。这$k$个框我们称之为Anchor(锚点?)。anchor的中心在滑动窗口的中心,对应不同的大小或横纵比。每个窗口,默认有3种大小、每种大小对应3种不同的横纵比,共计9个anchor。
Translation-Invariant Anchors
本文模型的得到Anchor满足平移不变性。